Дополнительные вопросы, которые я задаю на экзамене
Длительная практика принятия экзаменов по курсу Работа на ЭВМ и программирование на мех-мат ф-те МГУ заставила меня сделать два довольно странных (по крайней мере, для меня) вывода:
- На экзаменах я задаю довольно ограниченный набор дополнительных вопросов, знание которых я считаю необходимым для студентов, занимающихся программированием.
- Студенты довольно устойчиво на эти вопросы не отвечают.
Я не берусь судить, почему студенты на эти вопросы не отвечают. Ссылки почти на все эти вопросы есть во всех курсах по данному предмету, читаемых на мех-мате, что, вроде бы, делает студентов обязанными знать ответы на эти вопросы. Но вот устойчивость незнания корректных ответов меня давно уже изумляет. Посему, я решил выписать эти вопросы и дать ссылки на их корректные, на мой взгляд, ответы. Вопросы не всегда имеют академически-точную формулировку, ну да мне так нравится их задавать. Не взыщите. Отсутствие нижеприведенных вопросов в билетах освобождает вас от ответственности за незнание ответов на них, однако, все же, сильно рекомендуется для вашего же блага (глобального, а не локального) ответы на эти вопросы знать.
Очень бы
хотелось, чтобы вы знали, что самый раздражающий преподавателя аргумент
студента на экзамене: “а нам так на лекциях рассказывали”. Так говорить нельзя.
Вы уже взрослые люди и должны иметь свою точку зрения на обсуждаемые вопросы.
Даже если вы несете чушь (по мнению экзаменатора) и при этом считаете, что вам
так рассказывали на лекции, то это – ваши проблемы. Разумеется, здесь не идет
речь о вещах, не поддающихся разумной проверке на месте. Здесь говорится о
вопросах, проверить ответы на которые можно из
логических соображений.
К сожалению, мир устроен так, что людям свойственно ошибаться. А лекторы – люди. Во всех, известных мне лекциях есть ошибки. Это – нормально. Я исхожу из того, что если вы пересказываете такую ошибку, то это – опять же, ваша проблема. Вы учитесь на мех-мате, а не в техническом ВУЗе. Наша основная специальность – думать. Если не можете, то вы не предназначены для этого ф-та.
Сначала я напишу вопросы. Прочитайте и поймите, на что вы можете ответить. Ссылки на ответы я приведу в конце документа.
- Вы должны знать язык С. Без этого экзамен становится бессмысленным. Любой отвечаемый вами вопрос должен интерпретироваться небольшими примерами на языке С (С++). Не знаете языка – зубрите примеры. Хотя бы в этом случае у преподавателя будет спокойная совесть, когда он будет ставить вам отметку >2, при том, что, по его мнению, вы этой оценки недостойны. И не думайте, что хоть какому-то вменяемому преподавателю доставляет удовольствие ставить двойки. Ведь двойка, это – признание того, что он (преподаватель) выкинул кучу времени на учебу студентов впустую. А что есть дороже времени?
- Любимый вопрос по языку: как реализовать функцию, которая при первом вызове делает что-то одно, а при всех остальных – другое. К этому вопросу примыкает вопрос о времени жизни о области видимости переменных в языке С/С++. Кстати, для меня было большой неожиданностью узнать, что ответ на вопрос о времени жизни переменных в языках С и С++ различный.
- Механизм обработки прерываний, хотя бы на примере той машины, за которой вы в данный момент сидите.
- Виртуальная память в приличной ОС
(можно, конечно, сказать UNIX,
Linux, WindowsXXXX,
но это не существенно). Обычно, вопрос задается в виде: к каким конкретным
машинным командам [примерно] приводит кусок кода на С в приличной ОС:
char *s; s=12345; *s=123; - Кэш-память. Ассоциативная кеш-память. Объяснения должны быть вплоть до уровня конкретного алгоритма вычисления адреса в Кеш-памяти по адресу в физической памяти.
- Механизм передачи параметров в функции. Все вплоть до конкретных машинных команд. Вы должны знать ответ на банальный вопрос: а вызвать функцию, это – дорого? Т.е. насколько собственно вызов функции замедляет работу программы?
- Сколько может быть в программе локальных переменных? Например, какова максимально возможная глубина рекурсии вызова функции void f(int x); при тех ограничениях и допущения, которые вы сами хотите ввести. Еще лучше, если вы знаете существующие где-либо ограничения.
- Алгоритмы сортировки. Ну, самый убойный вопрос здесь – QuickSort. Существует элементарный способ завалить плохого студента. Надо попросить его рассказать хоть что-то, что он знает. С очень большой вероятностью студент выберет сортировку именно этим методом. Все. Можно потирать руки. Завалить на этом примере можно примерно 80% студентов (изо всех!). Есть два этапа заваливания: а)сначала надо попросить рассказать сам алгоритм в общем (если студент плохой, то он, наверняка, точно его не помнит); б)надо попросить точно выписать алгоритм. Второй этап – гроб. При, относительно, не сложной идее алгоритма, его конкретная реализация допускает море возможностей сделать фатальную (и для алгоритма, и для студента) ошибку.
- Теорема
о времени работы алгоритма QuickSort. Надо четко
понимать, что следующую формулировку этой теоремы вам не зачтет никто:
Среднее время работы алгоритма QuickSort равно O(n log2n), где n – количество элементов в массиве.
Среднее в каком смысле? Отвечать тут можно по-разному. Признаюсь, что не любой ответ, вычитанный из лекций, читаемых на мех-мате, меня устроит. - Формулировка
теоремы о наименьшем времени работы
алгоритмов, основанных на сравнениях. Надо четко понимать, что следующую
формулировку этой теоремы вам не зачтет никто:
Не существует алгоритма, способного отсортировать массив из n элементов за время, меньшее O(n log2n).
- Понятие нижних и верхних оценок. На мой взгляд (только на мой!), это – главные понятия читаемых курсов. Не уверен, что этот вопрос есть во всех мех-мат-овских курсах по данному предмету. Со всеми вытекающими выводами. Однако, с философской точки зрения, ответ на эти вопросы эквивалентен ответу на вопрос: что такое хорошо и что такое плохо. В конкретной области. Разве может быть что-то более важное?
- Хеширование. Любимый вопрос (на мой взгляд, совсем простой): надо рассказать, как реализовать исполнитель множество на основе хеширования (любого), который позволяет заносить слова в множество и определять: есть слово в множестве, или нет. Все это в терминах языка С.
- Семафоры. Здесь самый главный подвопрос: а зачем, вообще, это надо? Почему нельзя заменить такое громкое понятие семафора глобальной (в каком-то смысле) переменной и функциями на языке С, которые проверяют значение этой переменной, а потом делают соответствующие действия. Или, все-таки, можно? На самом деле можно. Да вот только, сомневаюсь, что, по крайней мере, на нашей кафедре найдется человек, кто с ходу выпишет соответствующие алгоритмы. Я с ходу тоже не выпишу.
0. Ничем помочь не могу. Если не потратили n-тое количество часов на программирование, то ситуация не лечится. Есть редкие примеры, когда человек эти часы потратил, но это не помогает. Чтобы не помогало совсем – такого не видел, но чтобы помогало плохо – видел. В последнем случае стараюсь войти в ситуацию.
1. Решается с помощью локальных статических переменных. Надо иметь в виду, что использование глобальных переменных – плохой тон. На самом деле, использование, вообще, статических переменных, это – всегда плохо (ну, например, статические переменные делают невозможным переход на использование написанных вами функций в многопоточной программе).
2. Вполне
конкретно, но не говорится, а как же возвращаться из прерывания? : http://www.opennet.ru/docs/RUS/os_unix/glava_12.html
Очень подробно и конкретно: http://www.xserver.ru/computer/computer/proc/1/4.shtml
. Конечно, не надо учить названия регистров и все тонкости. Я их, лично, не
помню.
Не надо читать Википедию!!! Крайне неинформативно!!!
Вот мой вариант ответа, подходящего для большинства современных платформ (не
для всех!!!, но это не существенно)
Прерывания
Процесс выполнения программы сводится, в конечном счете, к следующему. Программа
представляет собой набор последовательно записанных команд. Как правило,
существует регистр, в котором хранится номер текущий команды. Элементарный шаг
выполнения программы называется циклом.
В процессе исполнения цикла происходит выборка
команды и исполнение команды.
Сразу после выборки команды счетчик команд увеличивается так, что он указывает
на следующую команду.
Базовым
понятием при описании принципов действия ЭВМ является прерывание. Бывают прерывания четырех типов:
Программные прерывания
Аппаратные прерывания
Прерывания ввода/вывода
Прерывания по таймеру
При
исполнении прерывания происходит приостановка выполнения основной программы,
данные о адресе текущей команды (регистр с адресом текущей команды) и состояние
системы (например, регистр флагов) сохраняются (как правило, в стек) и
происходит передача управления на программу обработки прерывания. После ее
завершения состояние системы восстанавливается, и управление передается на
прерванную команду. Отметим, что часто перед обработкой прерывания приходится
сохранять гораздо больше данных. Например, обычно сохраняются значения всех
регистров. Но это уже - забота функции обработки прерывания.
Очевидно,
что прерывание не может наступать в произвольный момент. Поэтому в цикл
выполнения программы добавляется еще один этап: проверка наличия прерывания.
Именно на этом этапе будет возможен вызов прерывания. Если его поместить после
этапа исполнения команды, то в стеке надо будет сохранить текущий регистр с
адресом исполняемой команды (он увеличился сразу после выборки команды), а
после завершения прерывания надо вернуться по этому адресу.
В
процессе выполнения некоторых прерываний следует запретить вызов других
прерываний. Этот процесс называется блокировкой
вызовов прерываний. Вызов прерываний всегда блокируется при, собственно,
вызове прерывания, когда необходимые данные загружаются в стек и происходит
переход к процедуре исполнения прерывания.
Часто
прерывания реализуются с помощью таблицы
прерываний. Таблица прерываний представляет собой массив, в каждой ячейке
которой хранится адрес процедуры обработки прерывания и, возможно, некоторая
дополнительная информация. В этом случае каждое прерывание ассоциируется с
некоторым номером n и вызов
прерывания n ассоциируется
с вызовом процедуры обработки прерывания, адрес которой находится в ячейке
таблицы прерываний n.
Прерывания
очень полезны, например, для обработки операций ввода/вывода. Эти операции
весьма медлительны, поэтому было бы разумным (на самом деле так происходит
далеко не всегда) запустить эту процедуру и вернуть управление текущей программе.
Далее, когда от процессора будет требоваться вмешательство в процесс
ввода/вывода (например, данные попали, наконец, в буфер ввода/вывода), то
вызовется прерывание, которое обработает эти данные и вернет управление текущей
программе.
3. Хотелось бы услышать что-то включающее следующее.
Страничная организация памяти в
защищенном режиме
При
его реализации память разбивается на страница по 4K. Каталог страниц занимает одну страницу и содержит 1024 4-байтных
адресов обычных таблиц страниц. Каждая таблица страницы располагается в
отдельной странице. Обычный 32-битный адрес представляется следующим образом.
Биты 31-22 дают номер записи в каталоге страниц. Следующие 10 бит с номерами
21-11 дают номер записи в таблице страниц, на которую ссылается соответствующая
запись в каталоге страниц. И, наконец, последние младшие 12 бит дают смещение
внутри страницы. Данная адресация абсолютно прозрачна на пользовательском
уровне.
Для
ускорения процедуры используется специальный Кеш страниц TLB.
В
каждой записи в таблице страниц для задания адреса страницы используется 20
бит, а в остальных 12 содержится много дополнительной информации. Например, там
есть бит, указывающий – существует ли реально в памяти данная страница. Это
дает возможность вызывать соответствующее прерывание при обращении к странице,
которой нет в памяти. В современных операционных системах данное прерывание
используется для поддержки виртуальной памяти. Оно скачивает требуемую страницу
с диска (из файла подкачки), корректно устанавливает значения в соответствующей
записи в таблице дескрипторов, возможно, вытесняет некоторую страницу на диск и
возвращает управление в текущую программу.
Подробнее см., например, Базовые принципы функционирования вычислительных систем и ссылки, приведенные там.
4. Далее приводится пример необходимой информации для примера довольно старого процессора. Если хочется уточнить все это на примере новых процессоров – см. Internet.
Кэш-память
Cache
(запас) обозначает быстродействующую буферную память между процессором и
основной памятью. Кэш служит для частичной компенсации разницы в скорости
процессора и основной памяти - туда попадают наиболее часто используемые
данные. Когда процессор первый раз обращается к ячейке памяти, ее содержимое
параллельно копируется в кэш, и в случае повторного обращения в скором времени
может быть с гораздо большей скоростью выбрано из кэша.
При записи в память значение попадает в кэш, и либо одновременно копируется в
память (схема Write Through -
прямая или сквозная запись), либо копируется через некоторое время (схема Write Back -
отложенная или обратная запись). При обычной обратной записи, называемой также буферизованной сквозной записью, значение
копируется в память в первом же свободном такте, а при отложенной (Delayed Write) -
когда для помещения в кэш нового значения не оказывается свободной области; при
этом в память вытесняются наименее используемая область кэша.
Вторая схема более эффективна, но и более сложна за счет необходимости
поддержания соответствия содержимого кэша и основной
памяти.
Сейчас под термином Write Back в основном понимается
отложенная запись, однако это может означать и буферизованную сквозную.
Сквозная запись имеет существенный
недостаток: при выполнении подряд идущих операций записи в память кеш, практически, отключается и скорость записи
определяется только скоростью работы основной памяти. С другой стороны, в
многопроцессорных системах данный подход обеспечивает согласованность оперативной
памяти: данные, записанные различными процессорами, оказываются сразу же в
памяти. Однако, при этом кэш может оказаться несогласованным с памятью: один
процессор может не знать о том, что другой записал что-то в память. В этом случае
необходим цикл просмотра памяти для согласования памяти и кеша.
Отметим, что в реальных системах операций чтения памяти гораздо больше операций
записи (например, при обращении к командам используются вообще только операции
чтения). Реально, примерно 10% операций являются операциями записи, а остальные
– операциями чтения.
При использовании отложенной
записи запись в память осуществляется или при вытеснении данных из Кеша или при
особых событиях. Например, в Pentium-компьютерах
это может осуществиться даже программным путем с помощью посылки специальной
команды или с помощью аппаратного сигнала. Ясно, что смена строк Кеш-памяти для
случая отложенной записи требует больше времени, чем в случае сквозной
Кеш-памяти, т.к. перед записью строки в Кеш необходимо еще вытеснить текущую
строку Кеша в память.
При записи в память при
возникновении промахов (т.е.
ситуаций, когда данные по записываемому адресу не размещены в Кеше) возможно
использование двух стратегий: стратегия с
размещением и стратегия без
размещения. При использовании стратегии с
размещением данные параллельно записываются и в Кеш и в память. На самом
деле, обычно, сначала процессор записывает данные в основную память и
продолжает свою работу, а Кеш-контроллер параллельно
считывает соответствующую Кеш-строку из памяти в Кеш.
Данная стратегия имеет очень сложную реализацию, поэтому часто при записи
данных Кеш-память просто игнорируется (=стратегия без размещения).
Память для кэша состоит из собственно области данных, разбитой на
блоки (строки), которые являются элементарными единицами информации при работе кэша, и области признаков (tag), описывающей состояние строк
(свободна, занята, помечена для дозаписи и т.п.). В
основном используются две схемы организации кэша: с
прямым отображением (direct mapped),
когда каждый адрес памяти может кэшироваться только одной строкой (в этом
случае номер строки определяется младшими разрядами адреса), и n-связный
ассоциативный (n-way associative),
когда каждый адрес может кэшироваться несколькими строками. Ассоциативный кэш
более сложен, однако позволяет более гибко кэшировать данные; наиболее распространены
4-связные системы кэширования.
Процессоры 486 и выше имеют
также внутренний (Internal) кэш объемом 8-16 кб. Он
также обозначается как Primary (первичный) или L1 (Level 1 - первый уровень) в отличие от внешнего (External), расположенного на плате и обозначаемого Secondary (вторичный) или L2. В большинстве процессоров
внутренний кэш работает по схеме с прямой записью, а в Pentium
и новых 486 (Intel P24D и последние DX4-100, AMD
DX4-120, 5x86) он может работать и с отложенной записью. Последнее требует
специальной поддержки со стороны системной платы, чтобы при обмене по DMA можно
было поддерживать согласованность данных в памяти и внутреннем кэше. Процессоры Pentium Pro имеют также встроенный кэш второго уровня объемом 256
или 512 кб. Кеш L1 работает на частоте процессора, Кеш L2 работает на частоте шины. Т.о., используется то, что частота шины выше
частоты, с которой происходит выемка из памяти, а частота процессора выше
частоты шины. Например, в самых современных процессорах поддерживается тактовая
частота 3.2 ГГц, частота шины 800МГц, а самая совершенная память для PIV поддерживает частоту 400 МГц (отметим, что данные
частоты могут указывать не настоящие частоты, а частоты, на которых происходит
передача данных: за один такт может передаваться две порции данных).
В платах 386 чаще всего
использовался внешний кэш объемом 128 кб, для 486 - 128..256 кб, для Pentium - 256..512 кб.
Организация Кеш-памяти и
ассоциативная память в IBM PC-совместимых
ЭВМ
Рассмотрим
пример процессора i386,
имеющего 16K ассоциативной Кеш-памяти. Для ее
реализации используется быстрая (и дорогая) SRAM-память. Кеш-строка содержит
16 байт.
Внутри
Кеш-контроллера 32-битный адрес делится на три части:
·
Биты B31-B12 (20 бит) - адрес дескриптора
·
Биты B11-B4 (8 бит) - адрес набора
·
Биты B3-B2 (2 бит) - адрес слова (имеются в виду 4-байтные слова).
Т.о. для адреса x имеем:
D(x)=((x>>12)&((1<<20)-1)) номер дескриптора
S(x)=((x>>4)&((1<<8)-1)) номер набора
W(x)=((x>>2)&3) номер слова
B(x)=(x&3) номер байта
Ячейка Кеш-блока состоит из Кеш-директории и, собственно, Кеш-записи.
Кеш-директория содержит 20 бит со значением дескриптора данной Кеш-записи и 5 бит
признаков: бит защиты, бит занятости, 3 бита LRU (об этом – позже).
Бит
защиты предохраняет Кеш-запись от изменения и считывания в процессе цикла
записи Кеш-строки. Во время цикла записи он устанавливается равным 1, а в
остальное время он равен 0.
Бит
занятости указывает, на то, что
данная Кеш-строка реально отражает содержимое общей
памяти. Например, при изменении памяти в режиме DMA данный бит должен быть обнулен. Если данные в Кеше
соответствуют данным в основной памяти, то данный бит должен быть равным 1.
Отметим,
что когда мы говорили о 16K памяти, то
имели в виду лишь память, в которой будут храниться непосредственно данные.
Реально еще необходима память для хранения Кеш-директорий. Более того,
последняя память будет более часто использоваться и должна иметь большее
быстродействие.
Вся
Кеш память разбивается на магистрали.
В нашем случае используется 4 магистрали. Каждая магистраль состоит из массива строк по 16 байт. Для данного адреса x внутри
магистрали однозначно задается номер соответствующего набора = S(x). Т.о., размер магистрали равен длине строки умножить
на количество наборов = 28*24=4K, а т.к. у нас всего 4 магистрали, то размер всей
Кеш-памяти равен 16K.
Если
требуется внести в Кеш ячейку памяти с адресом x, то это можно сделать только вместе со всей строкой в
памяти, содержащей x. Итак,
пусть требуется внести в память строку, соответствующую адресу x. Мы сразу можем посчитать номер набора для этой строки
= S(x). Этот набор может быть расположен в одной из четырех
магистралей в наборе с номером S(x), поэтому
мы должны сравнить D(x) со
значениями дескрипторов в Кеш-директориях с номерами
изо всех магистралей, где в данных Кеш-директориях
бит защиты = 0 и бит занятости = 1.
Если
нашелся дескриптор, равный дескриптору вносимой строки, то считается, что
произошло Кеш-попадание и данные могут быть внесены в
соответствующую Кеш-строку. Иначе, произошел Кеш-промах. Если среди Кеш директорий с номером S(x) нашлась свободная директория (т.е. значение ее бита
занятости = 0), то мы можем разместить свои данные в соответствующей
Кеш-записи. Иначе нам придется выбрать одну из занятых Кеш-записей с номером S(x), вытеснить ее в обычную память и занести нашу Кеш-строку на ее место, модифицировав значения дескриптора
в Кеш-директории на значение D(x).
Простейшая
стратегия выбора подходящей магистрали – выбор ее случайным образом. Возможен
более аккуратный способ, когда выбирается давно использующаяся Кеш-запись. Это делается с помощью LRU-бит в
Кеш-директории. Например, это можно сделать следующим способом. Обозначим биты LRU: B0, B1, B2.
Если
произошел доступ к магистрали 0 или 1, то установим B0=1, при
этом если произошел доступ к магистрали 0, то установим B1=0, иначе
установим B1=1.
Если
произошел доступ к магистрали 2 или 3, то установим B0=0, при
этом если произошел доступ к магистрали 2, то установим B2=0, иначе
установим B2=1.
Т.о.
образом, бит B0 указывает,
к какой паре магистралей произошел последний доступ. Т.е. если B0==0, то
использовать для замещения нужно магистрали 0 или 1, а если если
B0==1, то
использовать для замещения нужно магистрали 2 или 3. Оставшиеся биты указывают,
какая из двух магистралей использовалась последней. Т.е. если B0==0&& B1==0, то
последней из двух магистралей 0 и 1 использовалась магистраль 0, поэтому для
замещения надо использовать магистраль 1.
Если
B0==0&& B1==1, то
последней из двух магистралей 0 и 1 использовалась магистраль 1, поэтому для
замещения надо использовать магистраль 0.
Если
B0==1&& B2==0, то
последней из двух магистралей 2 и 3 использовалась магистраль 2, поэтому для
замещения надо использовать магистраль 3.
Если
B0==1&& B2==1, то
последней из двух магистралей 2 и 3 использовалась магистраль 3, поэтому для
замещения надо использовать магистраль 2.
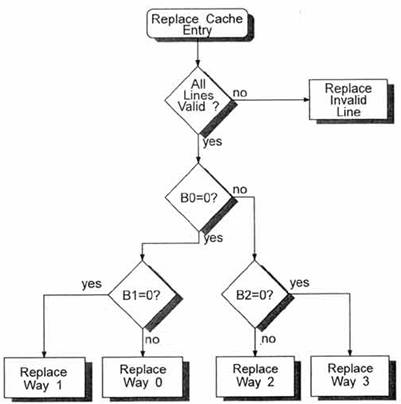
На
практике оказывается, что стратегия случайного замещения Кеш-записей
оказывается не намного хуже стратегии LRU.
5. Все
просто как шкаф. Все нижесказанное относится не ко всем архитектурам, но этого
достаточно. Обычно, параметры передаются в функции через стек. Существуют архитектуры,
где передача параметров идет через регистры, но мы об этом говорить не будем. Порядок
нижеописанных операций может быть другим, что ведет к некоторым особенностям механизма
вызова функций.
При вызове функции происходит загрузка параметров в системный стек, в
соответствии с их количеством и размерами. Далее происходит системный вызов call, который сохраняет текущее значение регистра (регистров)
с номером текущей команды в стек и загружает номер ячейки, на который следует
произвести переход, в регистр (регистры) с номером текущей команды. Начинается
выполнение функции. Внутри функции происходит выгрузка параметров из стека или
прямое обращения к участкам стека, в соответствии с типами и количеством
формальных параметров функции (именно поэтому фактические и формальные
параметры функции должны иметь одинаковые описания!). При завершении работы
функции происходит системный вызов rtn
(сообразите сами, что он делает) и происходит очистка стека от параметров
(сообразите, где эта очистка должна быть!).
Например, по данной ссылке все вышеописанные вещи объясняются более подробно http://devotes.narod.ru/Books/3/ch05_02a.htm
(если сайт умер, то текст можно прочитать здесь: http://lectures.stargeo.ru/add_qst/params.htm).
6. Ответ вытекает из ответа на предыдущий вопрос. Многие компиляторы по умолчанию ставят размер стека, равный 1M. Функция void f(int x); кладет в стек текущий выполняемый адрес и переменную int x. Например, на 32-битной архитектуре это может занимать 4байта+4байта=8байт. Т.о. максимально возможная глубина рекурсии в этих предположениях = 1024*1024/8=220/23=217.
7. Можно глянуть в мои лекции (там есть ссылки на литературу): http://lectures.stargeo.ru/add_qst/qsort.htm . Здесь следует обратить внимание на то, что стандартное представление алгоритма (с двумя рекурсивными вызовами) жизнеспособным не является. Вместо этого в жизни надо использовать алгоритм с одним рекурсивным вызовом (о чем в лекции и написано).
8. Ответ по той же ссылке: http://lectures.stargeo.ru/add_qst/qsort.htm . Отметим, что данную теорему можно формулировать несколько по-разному. Я привел формулировку, которая мне больше нравится, но возможны варианты.
9. Можно глянуть Лекцию 2 в моих лекциях (там есть ссылки на литературу): http://lectures.stargeo.ru/alg/algorithms.htm . Отмечу, что подход в этих лекциях несущественно отличается от подхода, принятого в лекциях, читаемых на мех-мате. Очень полезно понять, что это отличие несущественное.
10. Можно глянуть Лекции 2-3 в моих лекциях (там есть ссылки на литературу): http://lectures.stargeo.ru/alg/algorithms.htm . Повторю, что не гарантирую, что эти понятия есть во всех лекциях, читаемых на мех-мате. Если есть, то надо понять, как они соотносятся с тем, что написано у меня. Если нет – расслабляемся…
11. Ну, тут уж сами как-нибудь…
12. Можно глянуть пару моих лекций (ссылки там есть): http://lectures.stargeo.ru/add_qst/semaph.htm . Там много всего дополнительного, что необходимо понимать, отвечая на этот вопрос, но и ответ строго на данный вопрос есть. В сущности, самым главным словом, которое надо сказать при определении семафоров, это – атомарность. Операции семафора должны быть неразрывными, т.е. их надо непрерывно выполнять в текущем процессе (потоке), не пересекая с аналогичными операциями из других процессов (потоков). Следует понимать, что будет при нарушении этого принципа.