Оглавление
Распараллеливание
отдельных инструкций
Раздельное
использование переменных в параллельных потоках
Предельный минимум по OpenMP
OpenMP замечательно работает как в VisualStudio, так и в gcc.
В VisualStudio надо в меню Project/ Properties/ C/C++/ Language/ OpenMP Support установить значение Yes, что эквивалентно компиляции в командной строке с ключом –openmp .
В gcc
надо компилироваться с ключом –fopenmp
Например:
g++ -fopenmp -O3 File.cpp
Замечу, что без этих указаний код компилируется (и в VS, и в gcc), но реально OpenMP не используется.
Распараллеливание циклов
Привожу пример банальной программы, в которой от OpenMP используется всего один оператор #pragma (на самом деле, там использование двух совмещенных инструкций: '#pragma omp parallel' и '#pragma omp for')
#include <stdio.h>
#include <math.h>
#include <time.h>
int main(void)
{int
N=1000*1000*100,n2=30;
int i,*a=new int[N],*b=new int[N],*c=new int[N]; time_t t1,t2;
for(i=0;i<N;i++)
{a[i]=i;b[i]=i;}
printf("1\n");
time(&t1);
for(int I=0;I<n2;I++)
{
#pragma omp parallel for
for(i=0;i<N;i++)
a[i]=(int)(sqrt(b[i]*1.)*sqrt(1.*c[i]));
}
time(&t2);
printf("2:%d\n",(int)(t2-t1));
time(&t1);
for(int I=0;I<n2;I++)
{
for(i=0;i<N;i++)
a[i]=(int)(sqrt(b[i]*1.)*sqrt(1.*c[i]));
}
time(&t2);
printf("3:%d\n",(int)(t2-t1));
getchar();
return 0;
}
На gcc на хорошей машине я получил ускорение в 4 раза. На VS на ноутбуке - в 2 (хотя, это соответствует количеству процессоров).
По большому счету, это все, что для начала надо знать для использования OpenMP в рамках распараллеливания циклов с независимыми телами. ВСЕ!!!
Развиваться можно сильно и много. Но уже для более сложных задач (например, наличие критических секций).
По хорошему, надо добавить вызов функций (с примерными параметрами)
omp_set_dynamic(0);
omp_set_num_threads(4);
предварительно добавив
#include
<omp.h>
У меня все работало без этого.
Распараллеливание отдельных инструкций
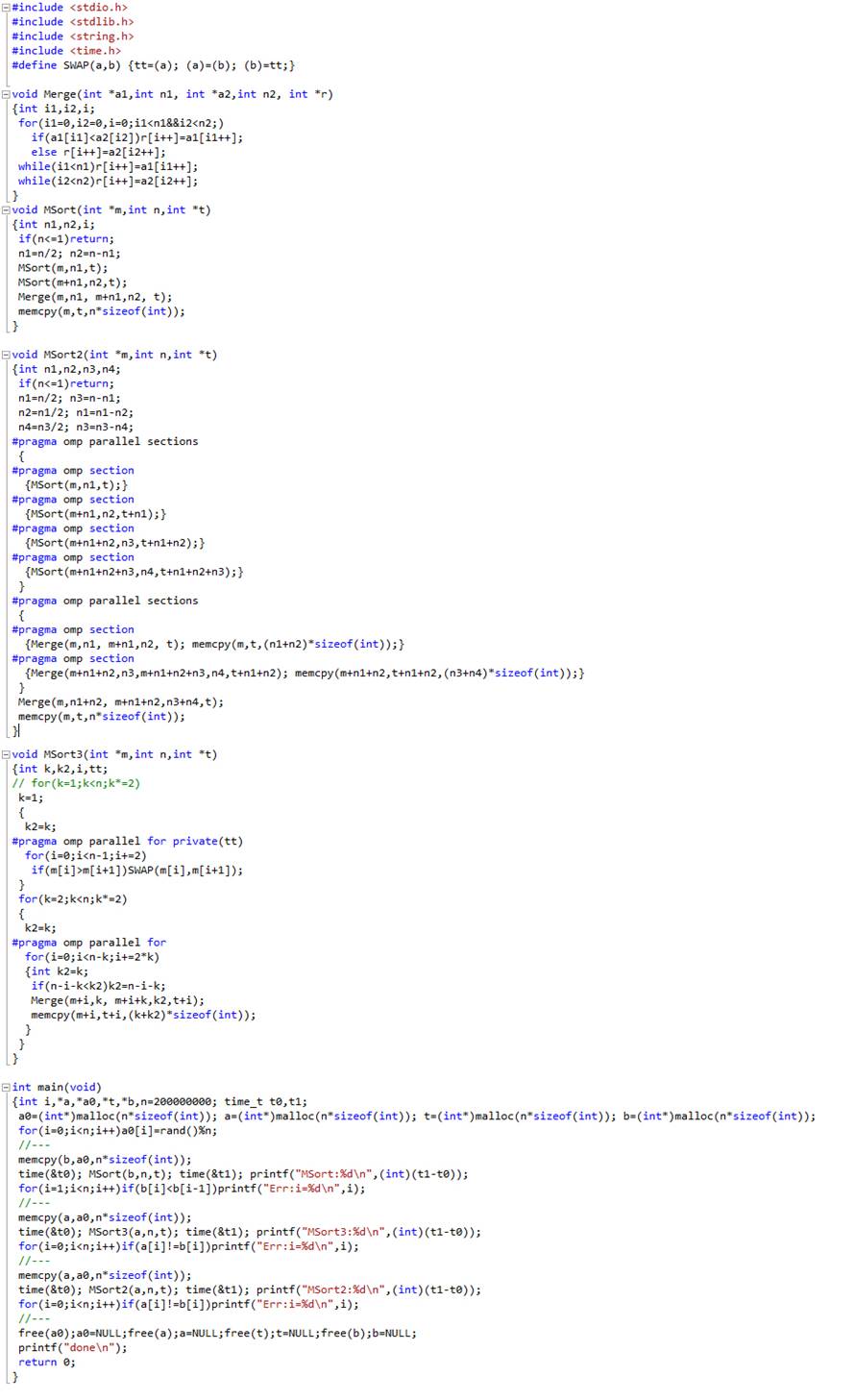
Для распараллеливания отдельных независимых кусков кода можно использовать инструкции '#pragma omp parallel sections' и '#pragma omp section'.
В следующем примере реализована программа сравнения обычного алгоритма сортировки слиянием с рекурсией с реализацией того же алгоритма с распараллеливанием на четыре потока. Распараллеливание оказывается весьма эффективным: на ноутбуке с двухъядерным процессором получаем ускорение более, чем вдвое (естественно, ценой полной нагрузки процессора).
Раздельное использование переменных в параллельных потоках
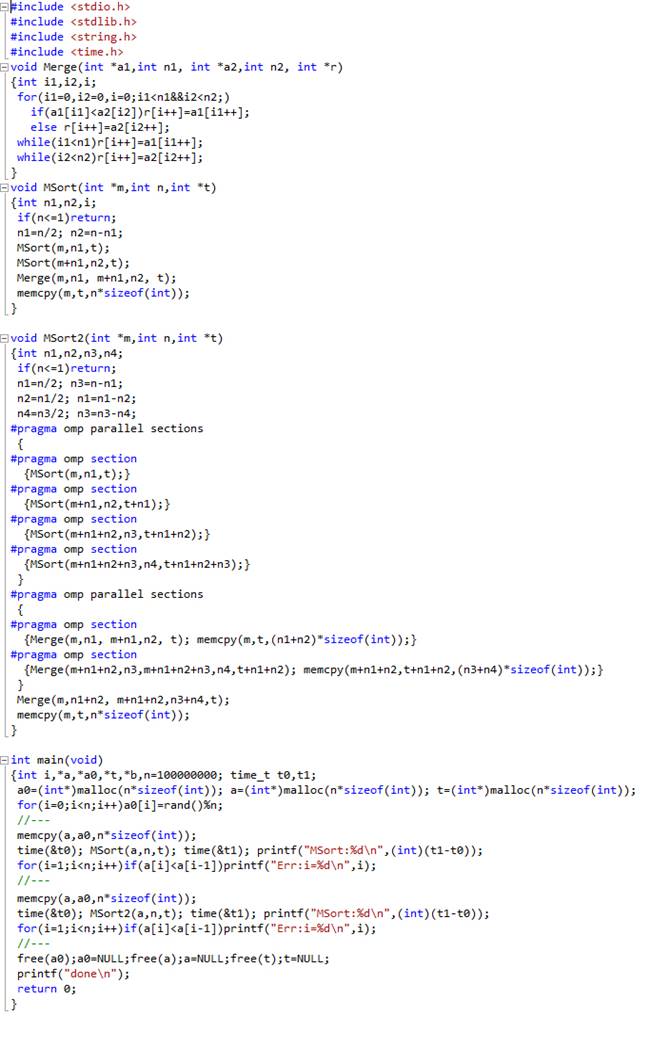
Следующий пример является расширением предыдущего. В нем сравниваются варианты распараллеливания алгоритмов сортировки слиянием с рекурсией и без рекурсии. В дополнение к рассмотренным выше инструкциям добавляется инструкция private(…), с помощью которой можно объяснить компилятору, что указанные в скобках переменные должны быть свои для каждого потока, выполняющего тело цикла.